TL;DR: StructLDM is a new paradigm (vs. existing 3D GAN) for 3D human generation from 2D image collections. We propose an structured auto-decoder to auto-decode human images/videos in different poses and from various camera viewpoints into a unified UV-aligned space, where we learn a structured latent diffusion model for 3D human generation.

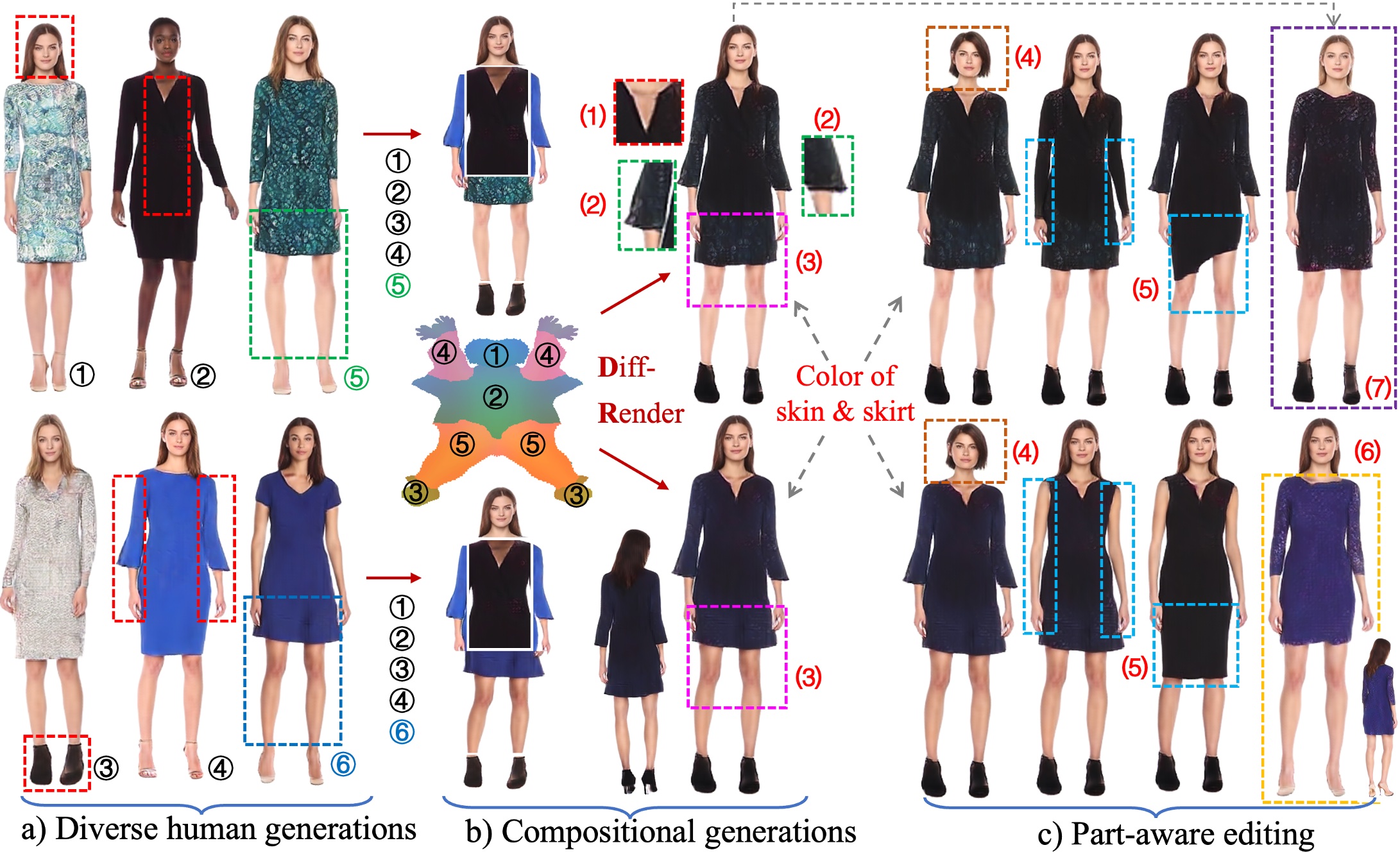
StructLDM generates diverse view-consistent humans, and supports different levels of controllable generation and editing, such as compositional generations by blending the five selected parts from a), and part-aware editing such as identity swapping, local clothing editing, 3D virtual try-on, etc. Note that the generations and editing are clothing-agnostic without clothing types or masks conditioning.