TL;DR: SurMo is a new paradigm for learning dynamic human rendering from videos by jointly modeling the temporal motion dynamics and human appearances in a unified framework based on a novel surface-based triplane.
SurMo effectively models the secondary motion of clothes, e.g., movements of the T-shirt induced by dancing.
Observations and Contributions:
- New Paradigm. We extend the existing well-adopted paradigm of "Pose Encoding → Appearance Decoding" to "Motion Encoding → Motion Decoding, Appearance Decoding", and found that a Motion Decoding module could significantly improve both the quantitative and qualitative rendering results. *Motion = Pose + Dynamics (e.g., velocity, motion trajectory)
- Dynamics Modeling. We explicitly model physical dynamics, and we are one of the early works that systematically analyze how human appearances are affected by temporal dynamics and found that the existing paradigm mainly synthesizes pose-dependent instead of time-varying appearances.
- Surface-based vs. Volumetric Motion Modeling. We compare the surface-based and volumetric triplane in motion modeling, and illustrate that surface-based triplane converges faster in training, and performs more effectively in handling self-occlusions and more efficiently in rendering images.
SurMo effectively models the secondary motion of clothes, e.g., movements of the T-shirt induced by dancing.
Observations and Contributions:
- New Paradigm. We extend the existing well-adopted paradigm of "Pose Encoding → Appearance Decoding" to "Motion Encoding → Motion Decoding, Appearance Decoding", and found that a Motion Decoding module could significantly improve both the quantitative and qualitative rendering results. *Motion = Pose + Dynamics (e.g., velocity, motion trajectory)
- Dynamics Modeling. We explicitly model physical dynamics, and we are one of the early works that systematically analyze how human appearances are affected by temporal dynamics and found that the existing paradigm mainly synthesizes pose-dependent instead of time-varying appearances.
- Surface-based vs. Volumetric Motion Modeling. We compare the surface-based and volumetric triplane in motion modeling, and illustrate that surface-based triplane converges faster in training, and performs more effectively in handling self-occlusions and more efficiently in rendering images.
Abstract
Dynamic human rendering from video sequences has achieved remarkable progress by formulating the rendering as a mapping from static poses to human images. However, existing methods focus on the human appearance reconstruction of every single frame while the temporal motion relations are not fully explored. In this paper, we propose a new 4D motion modeling paradigm, SurMo, that jointly models the temporal dynamics and human appearances in a unified framework with three key designs: 1) Surface-based motion encoding that models 4D human motions with an efficient compact surface-based triplane. It encodes both spatial and temporal motion relations on the dense surface manifold of a statistical body template, which inherits body topology priors for generalizable novel view synthesis with sparse training observations. 2) Physical motion decoding that is designed to encourage physical motion learning by decoding the motion triplane features at timestep t to predict both spatial derivatives and temporal derivatives at the next timestep t+1 in the training stage. 3) 4D appearance decoding that renders the motion triplanes into images by an efficient volumetric surface-conditioned renderer that focuses on the rendering of body surfaces with motion learning conditioning. Extensive experiments validate the state-of-the-art performance of our new paradigm and illustrate the expressiveness of surface-based motion triplanes for rendering high-fidelity view-consistent humans with fast motions and even motion-dependent shadows.
Method Overview
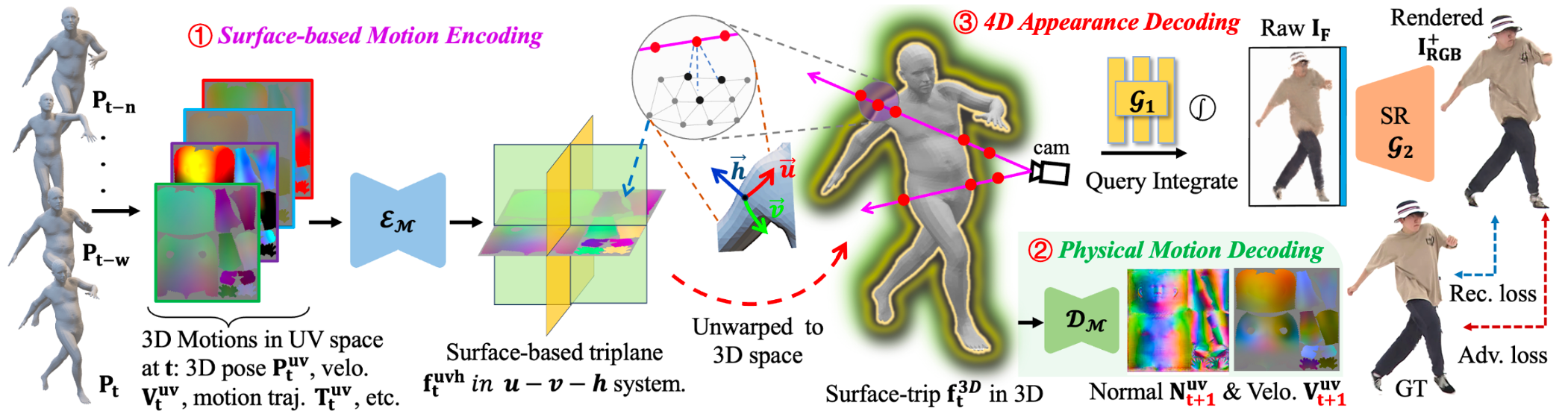 Given a set of time-varying 3D body meshes obtained from training video sequences, SurMo learns to synthesize high-fidelity appearances of a clothed human in motion via a feature encoder-decoder framework. In contrast to the existing well-adopted paradigm of "Pose Encoding → Appearance Decoding", we propose a new paradigm "① Motion Encoding (Pose + Dynamics, e.g., velocity, motion trajectory at timestep t ) → ② Physical Motion Decoding (predicting spatial and temporal motion derivatives, e.g., surface normal and velocity at timestep t+1) + ③ Appearance Decoding" that jointly models the temporal dynamics and human appearances in a unified framework. In addition, we propose to model motions on a novel surface-based triplane efficiently.
Given a set of time-varying 3D body meshes obtained from training video sequences, SurMo learns to synthesize high-fidelity appearances of a clothed human in motion via a feature encoder-decoder framework. In contrast to the existing well-adopted paradigm of "Pose Encoding → Appearance Decoding", we propose a new paradigm "① Motion Encoding (Pose + Dynamics, e.g., velocity, motion trajectory at timestep t ) → ② Physical Motion Decoding (predicting spatial and temporal motion derivatives, e.g., surface normal and velocity at timestep t+1) + ③ Appearance Decoding" that jointly models the temporal dynamics and human appearances in a unified framework. In addition, we propose to model motions on a novel surface-based triplane efficiently.
Volumetric Triplane vs. Surface-based Triplane
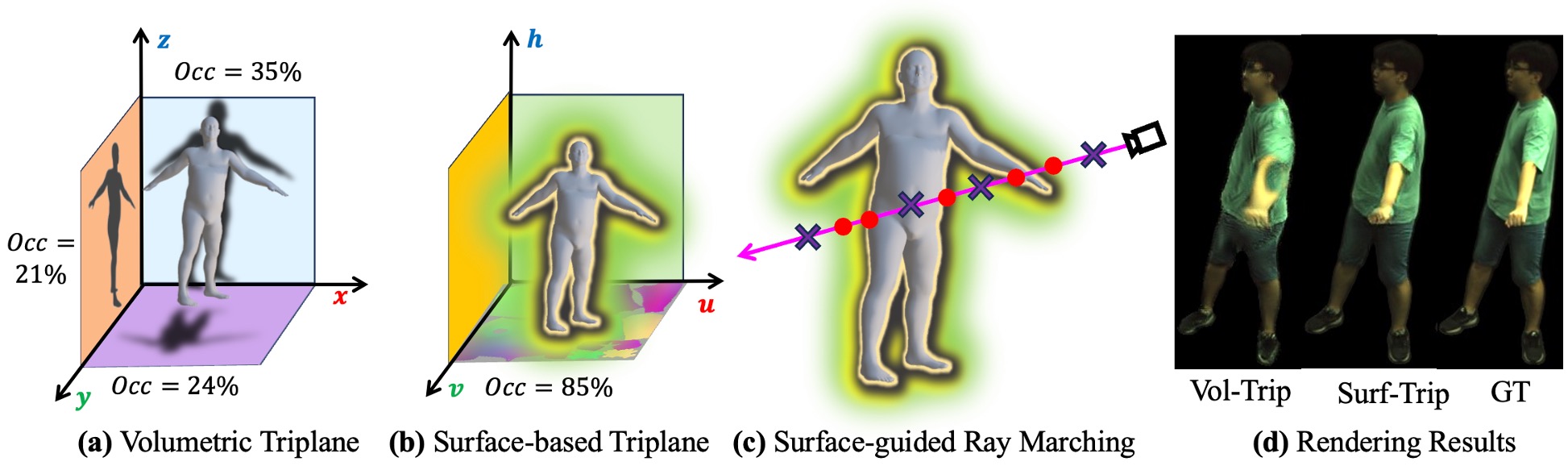
Volumetric triplane is a sparse representation for human body modeling, i.e., only 21-35% (occupancy rate) features are utilized to render the human under the specific pose, and hence the Vol-Trip fails to handle the self-occlusions effectively as shown in (d). In contrast, about 85% surface-based triplane features are utilized in rendering. In addition, with surface-guided ray marching, our method is more efficient by filtering out invalid points that are far from the body surface.
Time-Varying vs. Pose-Varying Appearances

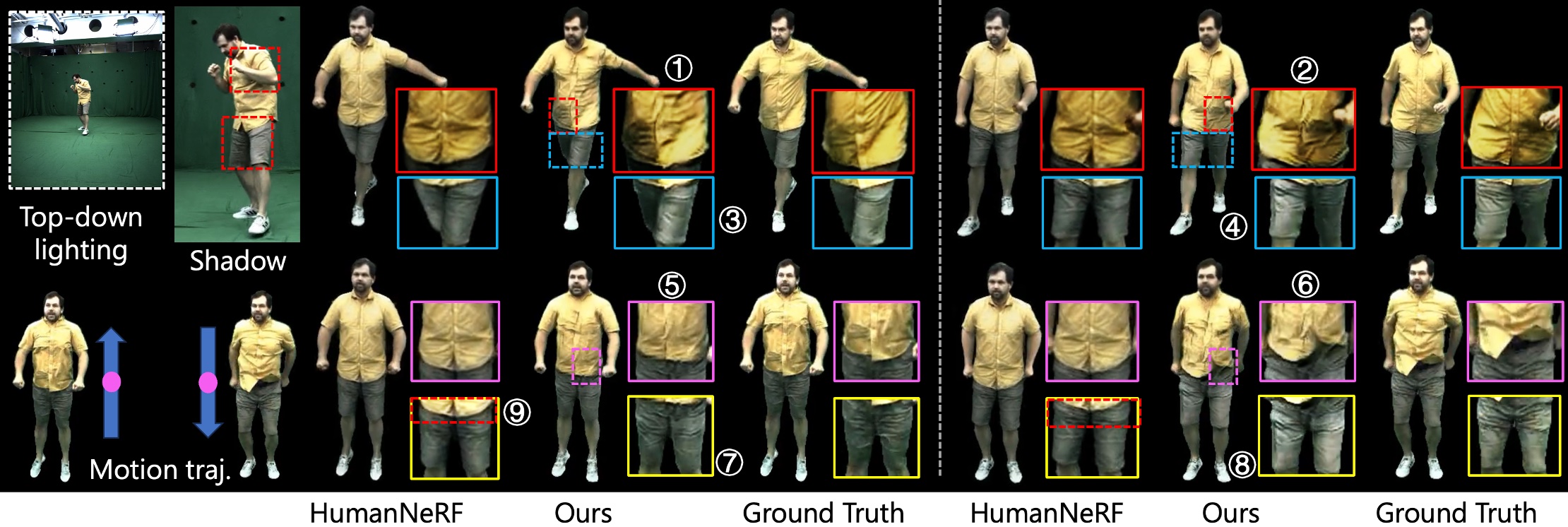
Novel view synthesis on two motion sequences S1 (swing arms left to right) and S2 (raise and lower arms). We specifically focus on the synthesis of time-varying appearances (especially T-shirt wrinkles), by evaluating the rendering results under similar poses yet with different movement directions, which are marked in the same color, such as the pairs of ①②, ③④, and ⑤⑥. Our new paradigm is capable of synthesizing high-fidelity time-varying appearances, whereas existing paradigm mainly synthesizes pose-dependent instead of time-varying appearances, i.e., HumanNeRF [Weng et al.] generates almost the same cloth wrinkles.
Render Motion-Dependent Shadows on MPII-RDDC
Novel view synthesis of time-varying appearances with both pose and lighting conditioning on MPII-RDDC dataset. The sequence is captured in a studio with top-down lighting that casts shadows on the human performer due to self-occlusion. In Row 1, we specifically focus on synthesizing time-varying shadows (e.g., ① vs. ②, and ③ vs. ④) for different poses with different self-occlusions. In Row 2, we evaluate the synthesis of: 1) time-varying appearances for similar poses occurring in a jump-up-and-down motion sequence, e.g., ⑤ vs. ⑥, 2) shadows ⑦ vs. ⑧, and 3) clothing offsets ⑤ vs. ⑥ .
Render Fast Motions on AIST++
Novel View Synthesis on ZJU_MoCap
Free View Synthesis
Comparisons to Baseline Methods
Full Video Demo
Acknowledgments
This study is supported by the Ministry of Education, Singapore, under its MOE AcRF Tier 2 (MOE-T2EP20221-0012), NTU NAP, and under the RIE2020 Industry Alignment Fund – Industry Collaboration Projects (IAF-ICP) Funding Initiative, as well as cash and in-kind contribution from the industry partner(s).
BibTeX
@misc{hu2024surmo,
title={SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering},
author={Tao Hu and Fangzhou Hong and Ziwei Liu},
year={2024},
eprint={2404.01225},
archivePrefix={arXiv},
primaryClass={cs.CV}
}