My research focuses on computer vision, graphics and GenAI, especially 3D reconstruction, neural rendering, 3D human motion capture, animation, and avatar creation.

|
College of Computing and Data Science, Nanyang Technological University, Singapore
Research Fellow, Jun. 2023 ~ present
Advisor: Prof. Ziwei Liu
Affiliated: S-Lab and MMLab@NTU (Director Prof. Chen Change Loy).
|

|
Department of Computer Science, University of Maryland, College Park, USA
Ph.D., Aug. 2018 ~ Jun. 2023
Supervisor: Prof. Matthias Zwicker
|

|
3DV Lab, Tsinghua University, Beijing, China
Research Intern, Apr. 2021 ~ Nov. 2021
Supervisor: Prof. Yebin Liu
|

|
Graphics, Vision & Video Group, Max Planck Institute for Informatics, Saarbrücken, Germany
Research Intern, Mar. 2020 ~ Sep. 2020
Supervisor: Prof. Christian Theobalt
|

|
Shanghai AI Lab, Shanghai, China
Research Intern, Apr. 2023 ~ Jun. 2023
Supervisor: Prof. Ziwei Liu
|

|
Intelligent Creation Lab, ByteDance Inc USA, Remote
Research Intern, Dec. 2021 ~ Jul. 2022
Supervisor: Dr. Hongyi Xu, Dr. Linjie Luo
|

|
Speech Group, Microsoft Research Asia (MSRA), Beijing, China
Research Intern, Jun. 2017 - Nov. 2017
Supervisor: Dr. Kai Chen
|
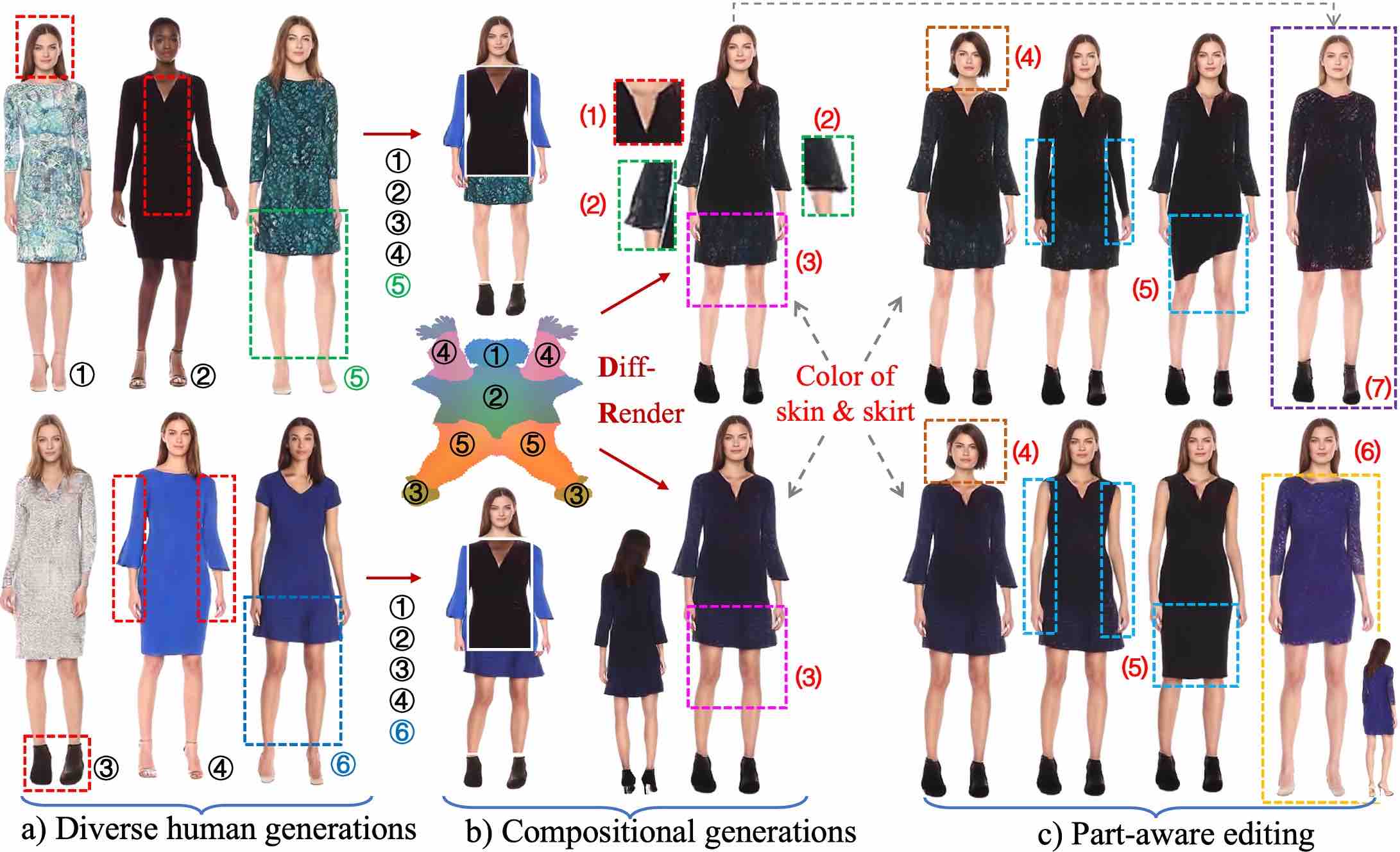 |
StructLDM: Structured Latent Diffusion for 3D Human Generation.
Tao Hu, Fangzhou Hong, Ziwei Liu.
European Conference on Computer Vision (ECCV 2024)
[Project Page] [Video]
[Code] [arXiv] [Media Coverage]
[Media Coverage in Chinese: 1, 2]
→ A new paradigm for 3D human generation from 2D image collections, with 3 key designs: a structured 2D latent space, a structured auto-decoder, and a structured latent diffusion model.
|
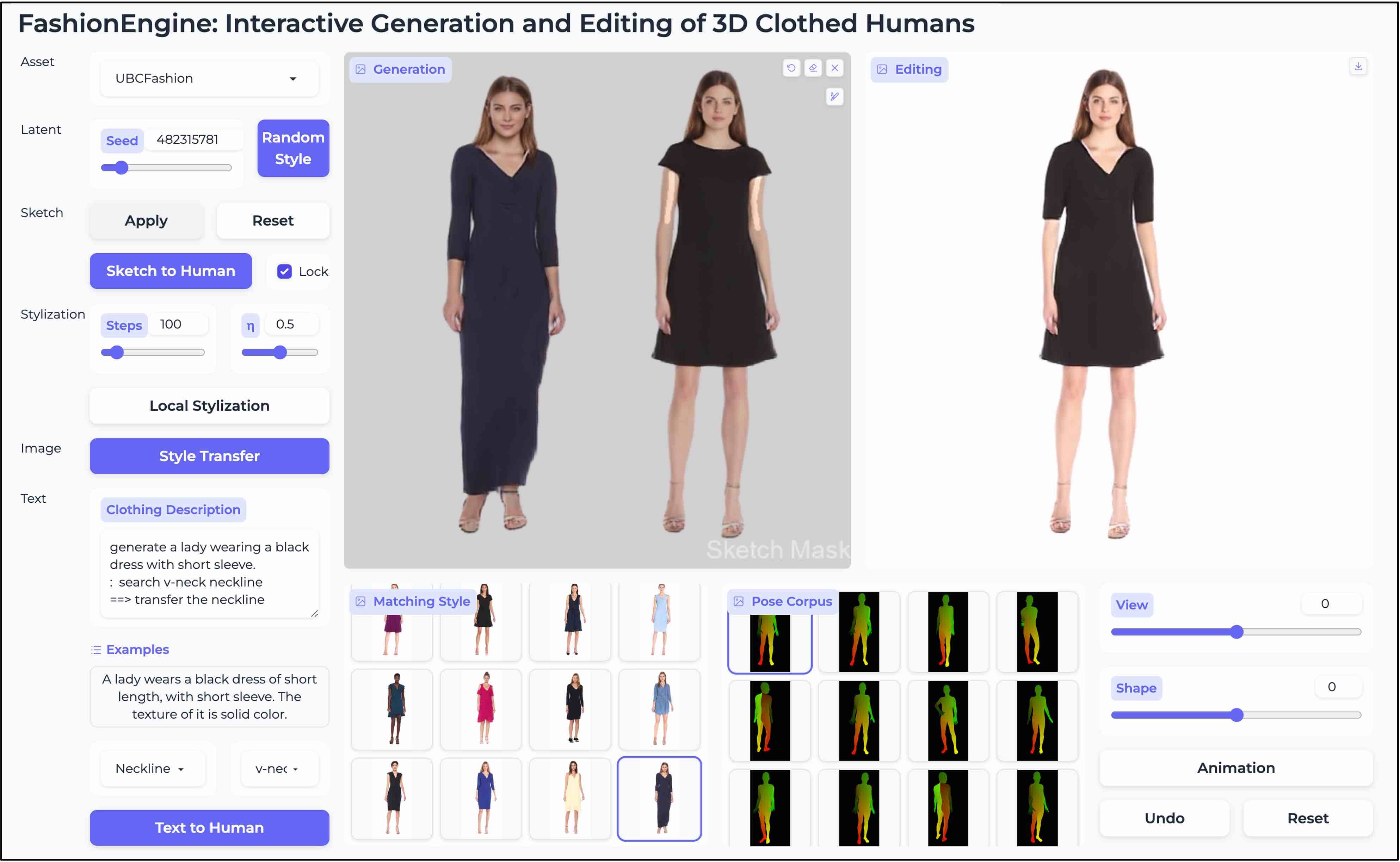 |
FashionEngine: Interactive 3D Human Generation and Editing via Multimodal Controls.
Tao Hu, Fangzhou Hong, Zhaoxi Chen, Ziwei Liu.
arXiv:2404.01655
[Project Page] [Video] [arXiv]
→ The first work that constructs an interactive 3D human generation and editing system with multimodal controls (e.g., texts, images, hand-drawing sketches) in a unified framework.
|
 |
HumanLiff: Layer-wise 3D Human Generation with Diffusion Model.
Shoukang Hu, Fangzhou Hong, Tao Hu , Liang Pan, Weiye Xiao, Haiyi Mei, Lei Yang, Ziwei Liu
International Journal of Computer Vision (IJCV), 2025
[Paper]
[Project Page]
[Code]
→ A diffusion-based approach for layer-wise 3D human generation.
|
 |
A Data-Centric Taxonomy for 3D Vision: Linking Representations, Aug-
mentation, and State-of-the-Art Learning Paradigms.
Hongyang Du, Runhao Li, Dawei Liu, Haoyuan Song, Qingyu Zhang, Yubo Wang, Jingcheng Ni, Shihang Gui,
Congchao Dong, Tao Hu
Technical Report, 2025.
[Paper]
|
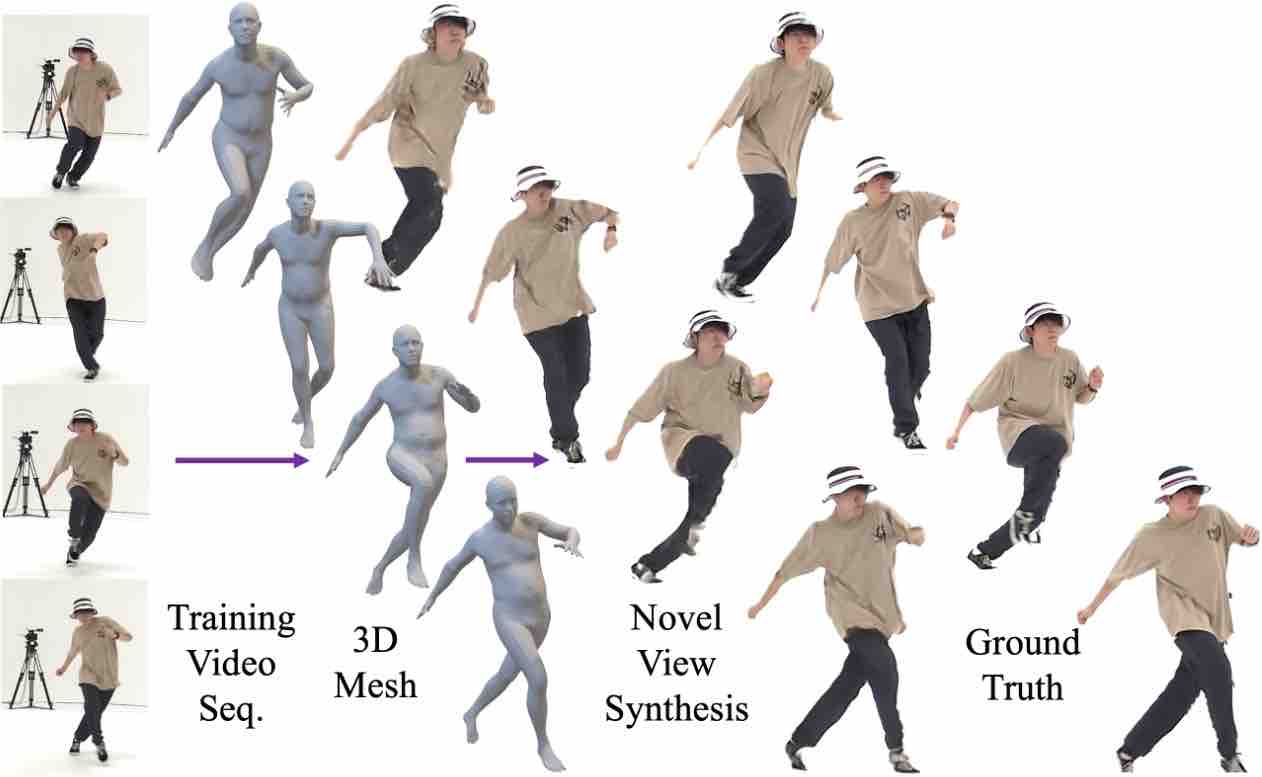 |
SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering.
Tao Hu, Fangzhou Hong, Ziwei Liu.
IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2024)
[Paper]
[Project Page]
[Video]
[Code]
[Media Coverage in Chinese: Media Heart, SenseTime Research ]
→ A new paradigm for learning dynamic human rendering from videos by jointly modeling the temporal motion dynamics and human appearances in a unified framework based on a novel surface-based triplane.
|
 |
HVTR++: Image and Pose Driven Human Avatars using Hybrid Volumetric-Textural Rendering.
Tao Hu, Hongyi Xu, Linjie Luo, Tao Yu, Zerong Zheng, He Zhang, Yebin Liu, Matthias Zwicker.
IEEE Transactions on Visualization and Computer Graphics (TVCG 2023)
[Paper]
[Project Page]
[Video]
[Code]
→ A virtual teleportation system using sparse view cameras based on a novel texel-aligned multimodal representation.
|
 |
HVTR: Hybrid Volumetric-Textural Rendering for Human Avatars.
Tao Hu, Tao Yu, Zerong Zheng, He Zhang, Yebin Liu, Matthias Zwicker.
International Conference on 3D Vision (3DV 2022)
[Paper]
[Project Page] [Video] [Poster] [arXiv]
[Code]
→ The first work that combines classical volumetric rendering with probabilistic generative models for efficient and realistic dynamic human rendering.
|
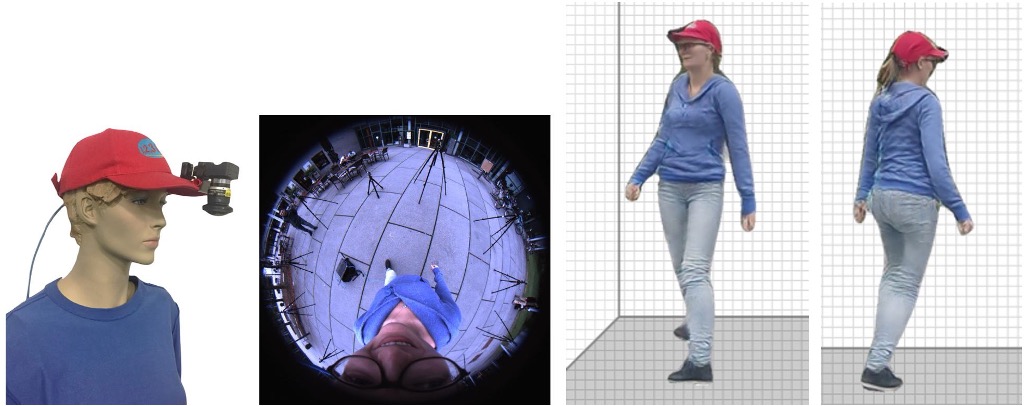 |
EgoRenderer: Rendering Human Avatars from Egocentric Camera Images.
Tao Hu, Kripasindhu Sarkar, Lingjie Liu, Matthias Zwicker, Christian Theobalt.
IEEE International Conference on Computer Vision (ICCV 2021)
[Paper] [Project Page] [Video] [Poster] [arXiv] [Media Coverage: SCIENCE & TECHNOLOGY NEWS]
→ A mobile virtual teleportation system integrating mobile motion capture and free-view rendering in a egocentric setup.
|
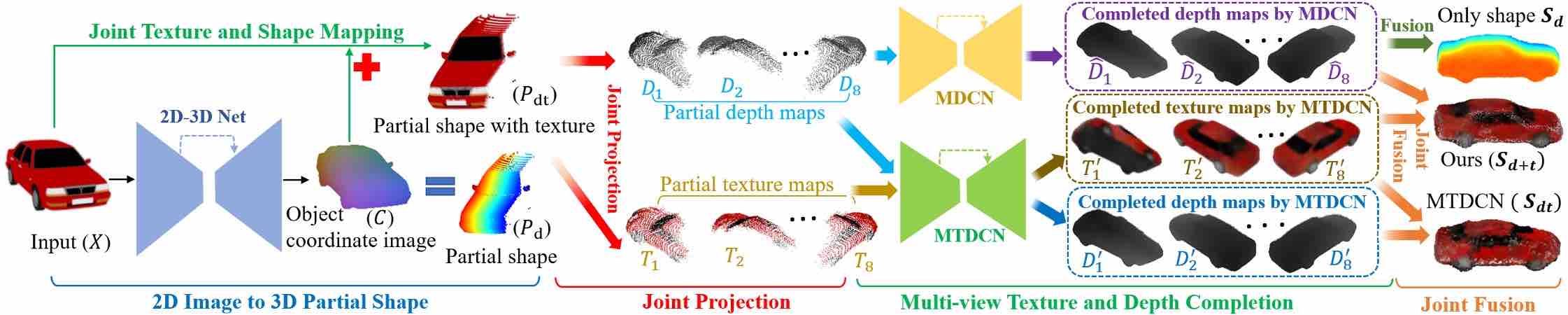 |
Learning to Generate Dense Point Clouds with Textures on Multiple Categories.
Tao Hu, Geng Lin, Zhizhong Han, Matthias Zwicker.
IEEE Winter Conference on Applications of Computer Vision (WACV 2021)
[Paper] [Code] [arXiv]
→ Extend the multi-view representation for generalizable geometry/texture reconstructions from single RGB images.
|
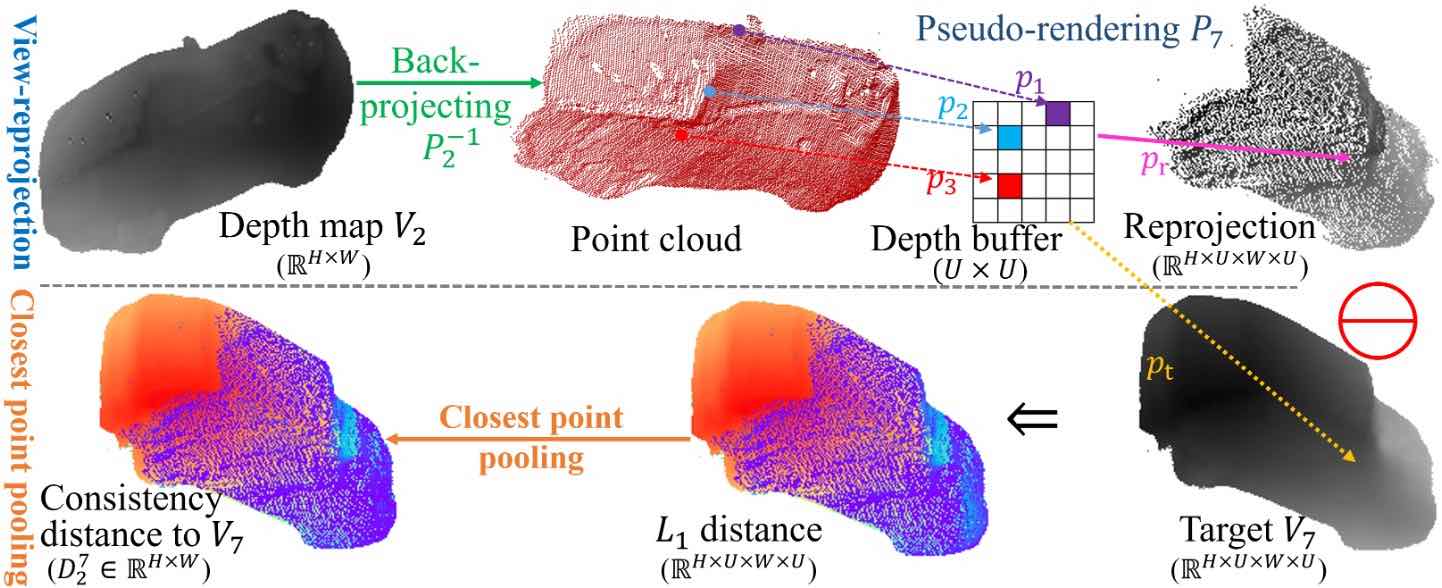 |
3D Shape Completion with Multi-view Consistent Inference.
Tao Hu, Zhizhong Han, Matthias Zwicker.
AAAI Conference on Artificial Intelligence (AAAI 2020, Oral, top 10% among accepted papers in 3D vision track)
[Paper] [Code] [arXiv]
→ Introduce a self-supervised multi-view consistent inference technique to enforce geometric consistency for multi-view representation.
|
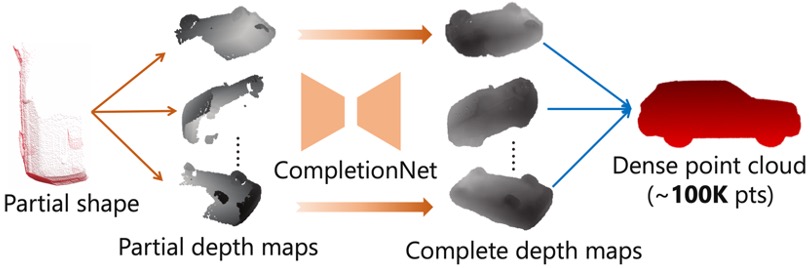 |
Render4Completion: Synthesizing Multi-view Depth Maps for 3D Shape Completion.
Tao Hu, Zhizhong Han, Abhinav Shrivastava, Matthias Zwicker.
IEEE ICCV Geometry Meets Deep Learning Workshop (ICCVW 2019, Oral)
[Paper] [Code] [arXiv]
→ Present multi-view based 3D shape representation with a multi-view completion net for dense 3D shape completion.
|
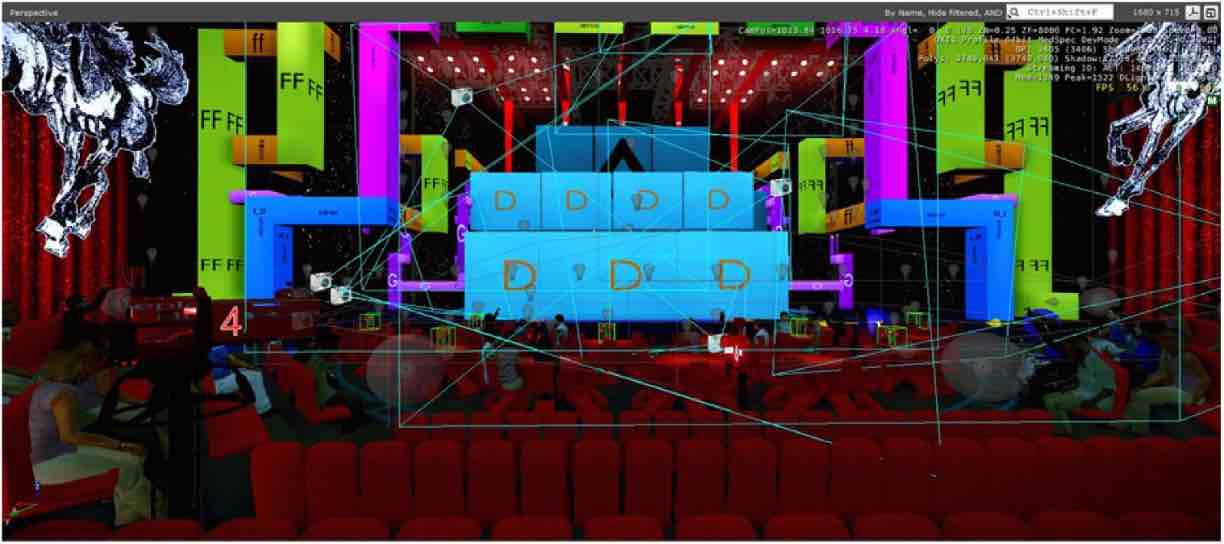 |
A Parallel Video Player Plugin for CryEngine.
Tao Hu, Gangyi Ding, Lijie Li, Longfei Zhang.
Highlights of Sciencepaper, Chinese Journal, May 2016.
→Propose a parallel video player plugin for CryEngine3 for a speedup from 16 FPS to 54 FPS at a large-scale virtual stage with 40 LED screens playing videos simultaneously for digital performance.
|
Teaching Assistant, Dept. of Computer Science, UMD.
