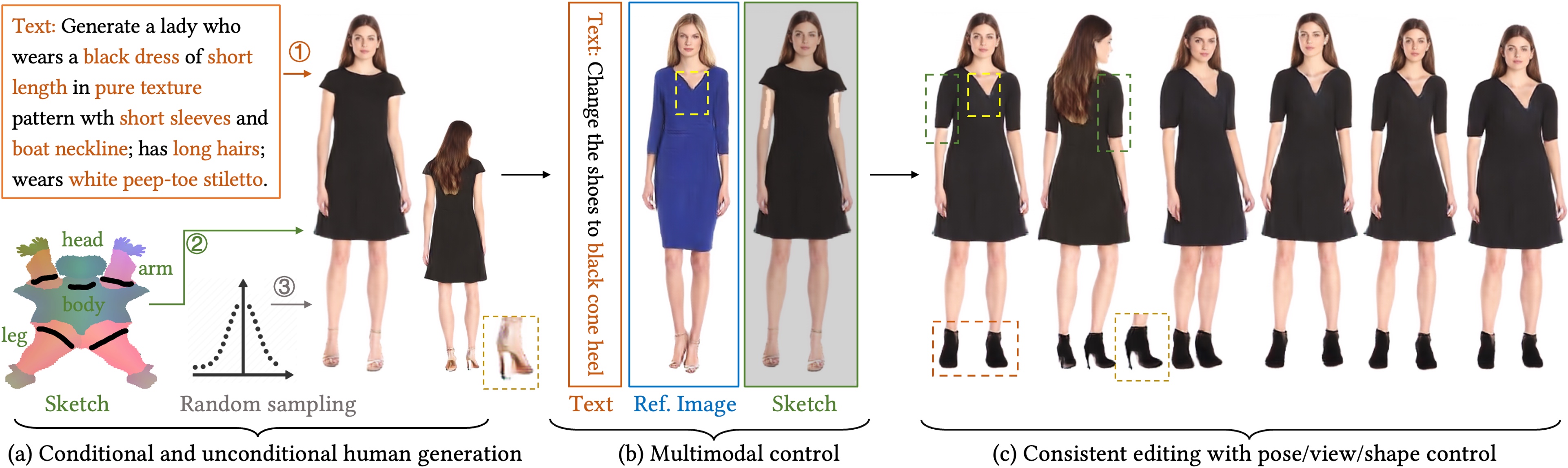
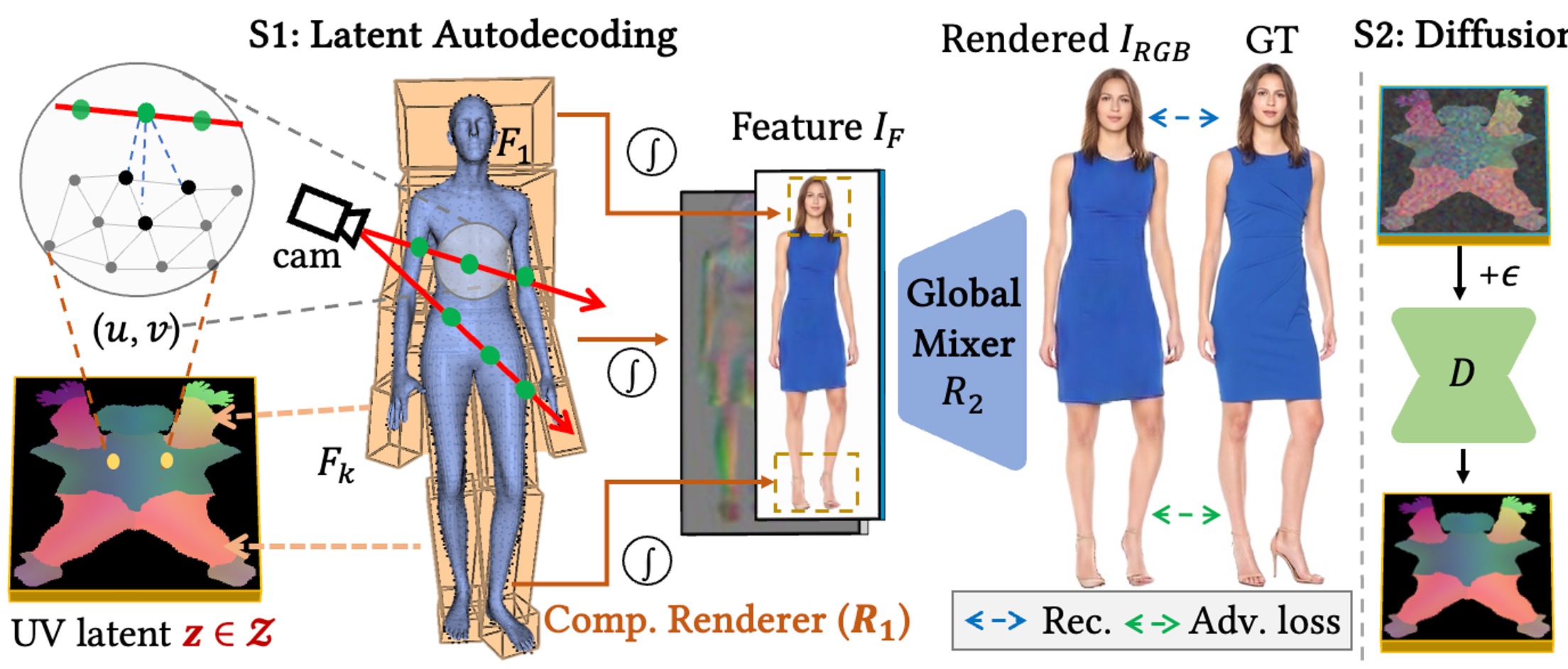
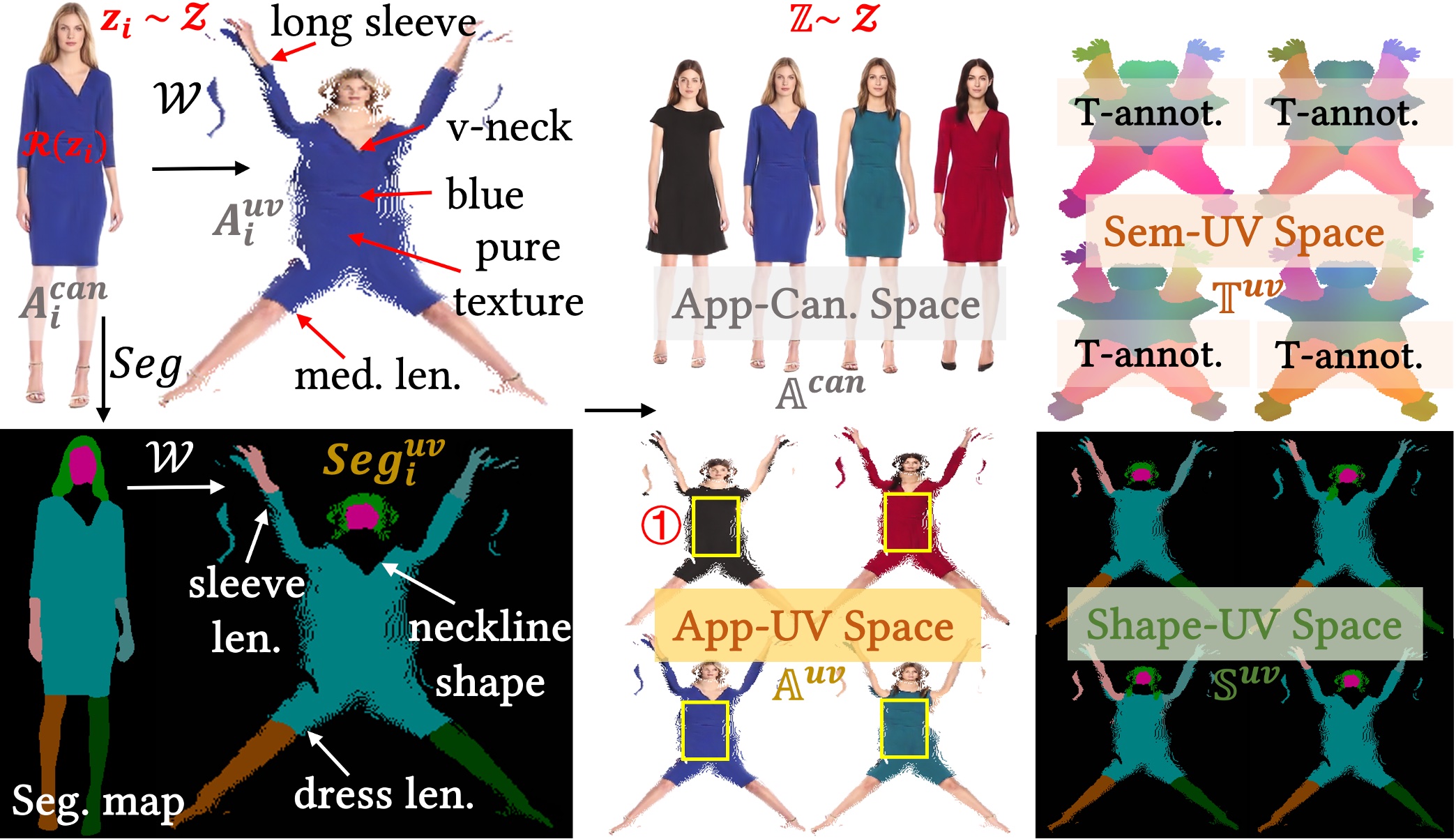
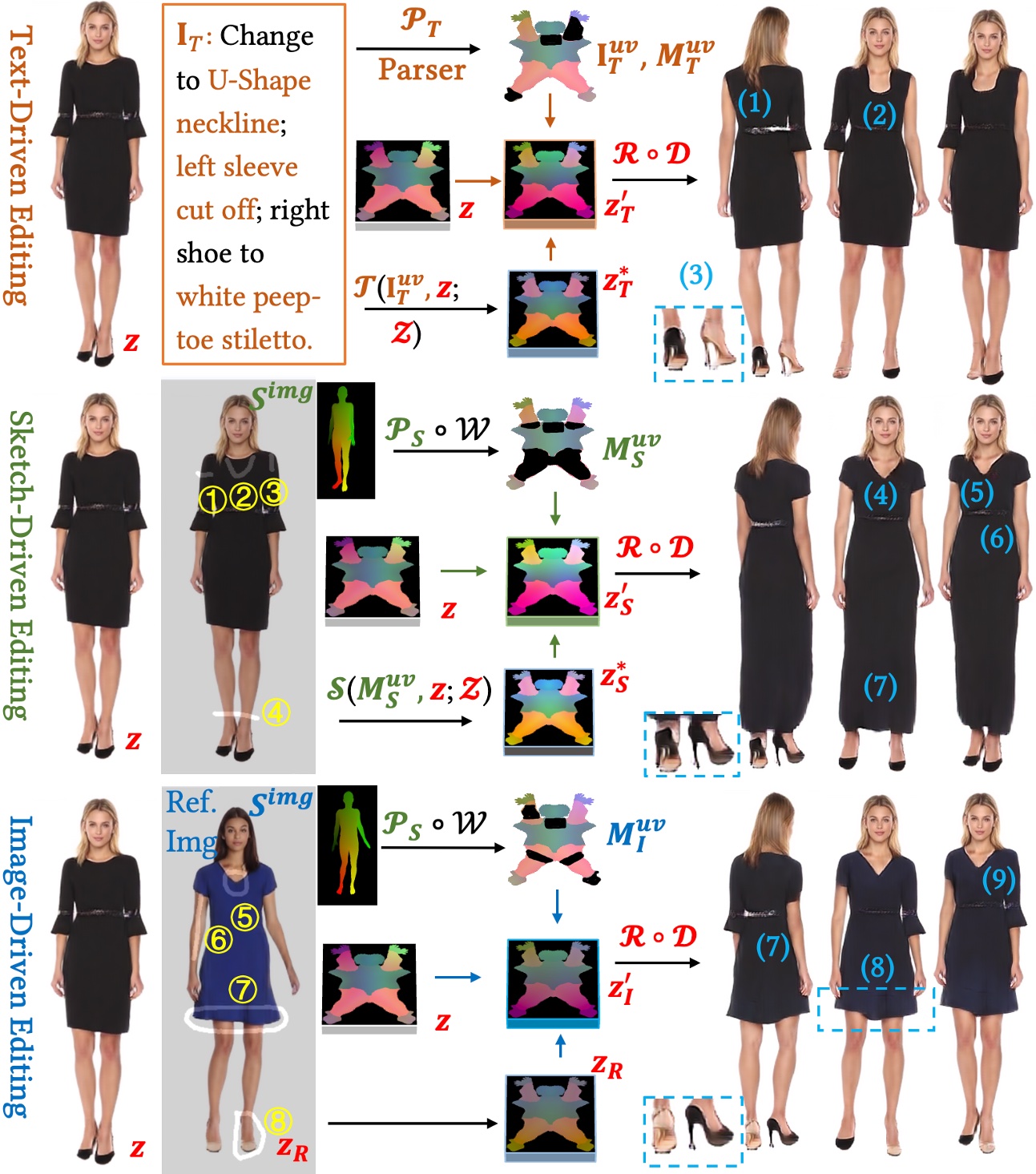
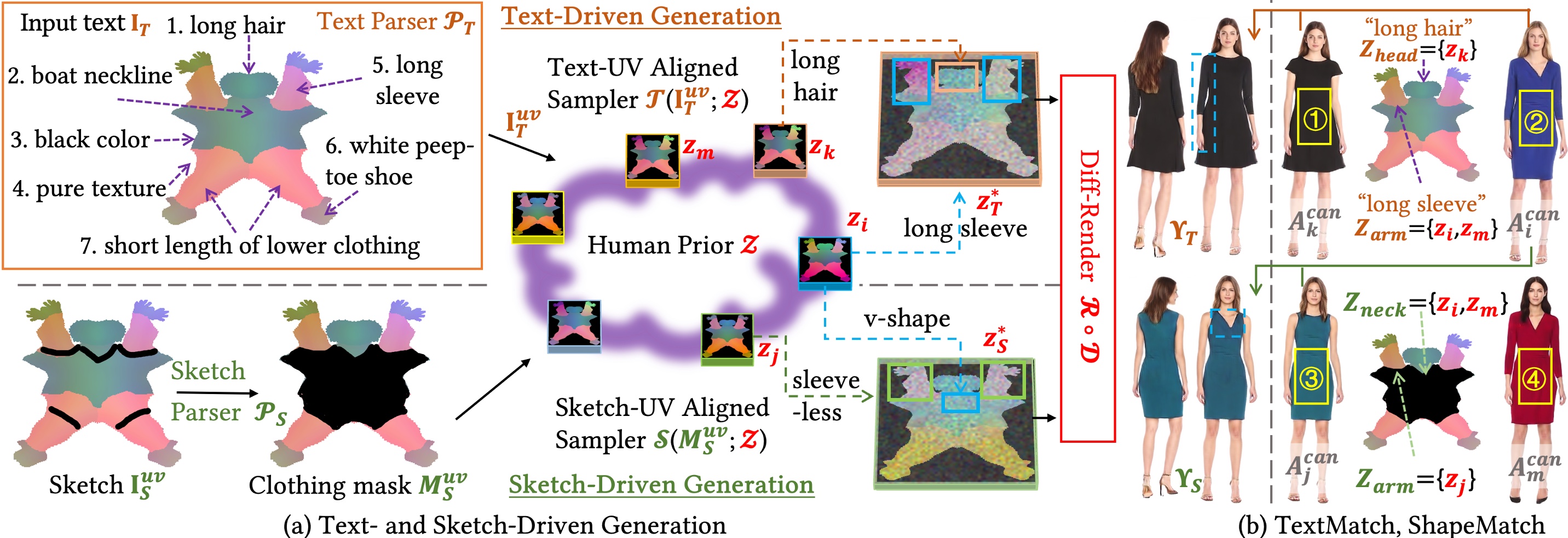
We present FashionEngine, an interactive 3D human generation and editing system that creates 3D digital humans via user-friendly multimodal controls such as natural languages, visual perceptions, and hand-drawing sketches. FashionEngine automates the 3D human production with three key components: 1) A pre-trained 3D human diffusion model that learns to model 3D humans in a semantic UV latent space from 2D image training data, which provides strong priors for diverse generation and editing tasks. 2) Multimodality-UV Space encoding the texture appearance, shape topology, and textual semantics of human clothing in a canonical UV-aligned space, which faithfully aligns the user multimodal inputs with the implicit UV latent space for controllable 3D human editing. The multimodality-UV space is shared across different user inputs, such as texts, images, and sketches, which enables various joint multimodal editing tasks. 3) Multimodality-UV Aligned Sampler learns to sample high-quality and diverse 3D humans from the diffusion prior. Extensive experiments validate FashionEngine's state-of-the-art performance for conditional generation/editing tasks. In addition, we present an interactive user interface for our FashionEngine that enables both conditional and unconditional generation tasks, and editing tasks including pose/view/shape control, text-, image-, and sketch-driven 3D human editing and 3D virtual try-on, in a unified framework.